

计算机三级(数据库技术)模拟试卷75
选择题
1.下列不属于数据库应用系统物理设计阶段活动的是( )。(D)
A. 数据库物理结构设计
B. 数据库事务详细设计
C. 应用程序详细设计
D. 数据库备份与恢复设计
解析:物理设计阶段的活动主要有:确定存储结构、存取路径的选择和调整、确定数据存放位置和确定存储分配。数据库备份与恢复设计属于数据库日常维护活动。
2.在一个ER图中,包含三个实体集,两个二元一对多联系,两个二元多对多联系,则将该ER图转化为关系模型后,得到的关系模式个数是( )。(B)
A. 4个
B. 5个
C. 6个
D. 7个
解析:ER图向关系模式转换涉及到两方面:①实体的转换;②实体间联系的转换。
实体的转换:在从ER图转换为关系模式时,一个实体就转换成一个关系模式,实体的属性就是关系模式的属性,实体的键就是关系的主键。
实体间联系的转换:实体间存在三种联系,即1:1(一对一),1:m(一对多),m:n(多对多)。
由题目可知,该题中有三个实体,二个1:m(一对多)联系,二个m:n(多对多)联系。三个实体和二个m:n(多对多)联系可以转换为单独的模式,二对1:m(一对多)联系需要合并到实体中去。因此最终可以得到5个模式,故选择B选项。
3.DFD建模方法由四种基本元素组成,其中用来描述数据的提供者或使用者的是( )。(D)
A. 数据流
B. 处理
C. 数据存储
D. 外部项
解析:DFD的主要组成包括外部实体(外部项)、处理过程、数据存储和数据流。外部实体指系统之外而又和系统有联系的人或事物,说明了数据的外部来源和去处。处理指对数据逻辑处理,也就是数据变换,它用来改变数据值。数据流是指处理功能的输入输出,数据存储表示数据保存的地方,它用来存储数据。
4.从功能角度数据库应用系统可以划分为四个层次,其中负责与DBMS交互以获取应用系统所需数据的是( )。(C)
A. 表示层
B. 业务逻辑层
C. 数据访问层
D. 数据持久层
解析:数据库应用系统从功能角度可以划分为以下四个层次。
①表示层:用于显示数据和接收用户输入的数据。(一般为Windows应用程序或Web应用程序)。
②业务逻辑层:是表示层和数据访问层之间的桥梁,主要负责数据的传递和处理。
③数据访问层:实现对数据的保存和读取操作。可以访问关系数据库、文本文件或XML文档等。
④数据持久层:以程序为媒介把表现层或服务层的数据持久,它是位于物理层和数据访问层之间。
5.现有商品表(商品号,商品名,商品价格,商品描述),销售表(顾客号,商品号,销售数量,销售日期)。关于性能优化有以下做法:
Ⅰ.因为很少用到商品描述属性,可以将其单独存储
Ⅱ.因为经常按照商品名查询商品的销售数量,可以在销售表中添加商品名属性
Ⅲ.因为经常执行商品表和销售表之间的连接操作,可以将它们组织成聚集文件
Ⅳ.因为经常按照商品号对销售表执行分组操作,可以将销售表组织成散列文件
以上做法中,正确的是( )。(D)
A. 仅Ⅰ和Ⅱ和Ⅲ
B. 仅Ⅰ、Ⅱ和Ⅳ
C. 仅Ⅱ、Ⅲ和Ⅳ
D. 全部都是
解析:Ⅰ:因为很少用到商品描述属性,系统在查询时也就很少查询,因此可以将其分割,这样虽然破坏了表的整体性,却可以将系统得到优化。
Ⅱ:增加冗余列是指在多个表中增加具有相同语义的列,它常用来在查询时避免连接操作,值得一提的是,主码和外码在多表中重复出现不属于冗余列,这里指得冗余列是非关键字字段在多表的中的出现。
由于表的连接操作是比较费时的,如果在表中增加冗余列,则在行上执行查询操作时不需要进行表的连接操作,从而提高了查询效率。
Ⅲ:一个聚集是一组表,可将经常一起使用的具有同一公共列值的多个表中的数据行存储在一起。对于经常频繁一起查询的表,使用聚集比较方便。
Ⅳ:通常在运行Order By和Group By语句时会涉及到排序的操作,尤其是对大型的表进行重复的排序,会引起磁盘很大的开销。而散列文件的优点是:文件随机存放,记录不需进行排序;插入、删除方便;存取速度快;不需要索引区,节省存储空间。因此带有Order By和Group By的表可以使用散列文件存储,提高查询效率。
6.已知有关系:学生(学号,姓名,年龄),对该关系有如下查询操作:
SELECT 学号FROM 学生
WHERE姓名LIKE’张%’AND年龄!=15
为了加快该查询的执行效率,应该( )。(B)
A. 在学号列上建索引
B. 在姓名列上建索引
C. 在年龄列上建索引
D. 在学号和年龄列上建索引
解析:使用索引的原则如下。
①在需要经常搜索的列上创建索引。
②主键上创建索引。
③经常用于连接的列上创建索引。
④经常需要根据范围进行搜索的列上创建索引。
⑤经常需要排序的列上创建索引。
⑥经常用于Where子句的列上创建索引。
根据索引建立规则A和B选项都符合建立索引的条件。但是一般Where语句在执行时要执行全表检索寻找符合条件的内容,这本身就是很消耗时间的过程,尤其对于大型的表格更加消耗时间。本题查询过程中会首先执行“姓名LIKE’张%’”,如果条件为真则执行“年龄!=15”语句。由此可见本题查询时间主要消耗在Where语句上,因此在Where语句上建立索引可以提高查询的效率。
7.已知有关系R(A,B,C),其中A是主码,现有如下创建索引的SQL语句;
CREATE CLUSTERED INDEX idxl ON R(B)
则下列说法中正确的是( )。(B)
A. idxl既是聚集索引,也是主索引
B. idxl是聚集索引,但不是主索引
C. idxl是主索引,但不是聚集索引
D. idxl既不是聚集索引,也不是主索引
解析:关键字CLUSTERED表明该索引属于聚集索引,可以排除C、D选项。由于建立在主码上的索引才是主索引,所以A选项错。故选择B选项。
8.在完成数据库的物理设计之后,就进入数据库系统的实施阶段。设有下列活动:
Ⅰ.创建数据库
Ⅱ.装载数据
Ⅲ.编写应用程序
Ⅳ.数据库监控与分析
Ⅴ.数据库性能优化
上述活动中,属于数据库系统实施阶段任务的是( )。(A)
A. 仅Ⅰ、Ⅱ和Ⅲ
B. 仅Ⅰ、Ⅱ和Ⅳ
C. 仅Ⅰ、Ⅱ和Ⅴ
D. 仅Ⅰ、Ⅱ、Ⅲ和Ⅳ
解析:数据库实施阶段包括:建立数据库结构、数据加载、事务和应用程序的编码及测试、系统集成、测试与试运行、系统部署。Ⅳ、Ⅴ属于数据库运行管理与维护阶段内容。故选择A选项。
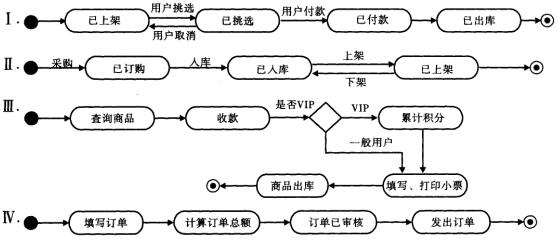
9.在使用UML对数据库应用系统进行建模的过程中,状态图和活动图是常见的动态建模机制。有下列状态图和活动图:
本文档预览:3600字符,共21063字符,源文件无水印,下载后包含无答案版和有答案版,查看完整word版点下载
